The publication annotation application was designed in the Global Information Systems (GlobIS)
research group at ETH Zurich to support researchers in their annotations, recommendations
and cross-referencing of articles. The application domain chosen for this demonstrator was the Paper++
project database providing information about related technologies, publications and contact persons. Some of
the publications stored in the database were augmented in the printed version with links directly into the database.
The prototype of the publication annotation application was another early application that used barcode technology
to simulate interaction with digital pens. A publication augmented with digital information from the database is
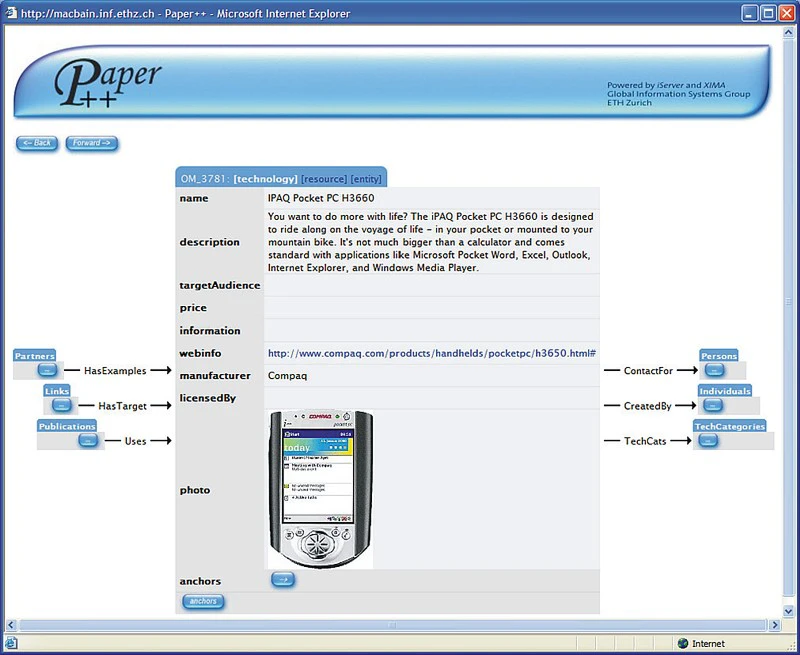
shown in Fig. 1. After selecting the highlighted word 'Pocket PC', a user immediately gets detailed information
displayed in a web page about the Pocket PC concept introduced in this part of the document together with links
to various relevant websites and also lists of partners and publications based on this technology as illustrated
in the figure below.
Fig. 1: Annotated research papers
What is the domain of discourse of such a publication annotation application? There are two possible
answers — the specific research domain, e.g. interactive paper, or the general research activity of
literature search and survey. Clearly, the former is much more specific and a system to support it requires
a database about interactive paper representing domain-specific concepts such as digital pens and position
encodings. The second is much more general and only requires a database that knows about concepts such as
citations, references, annotations etc. which enables linking between different articles and information
about the authors of those articles. While the data for this prototype is based on the interactive
paper domain, the application’s information model is a very general one representing concepts such as
articles, authors and technologies. This means that the prototype is not limited to be used in a specific
application domain such as the Paper++ project, but could be used by any scientific research community.
Fig. 2: Result page with metadata
For the publication annotation application, we made use of XIMA's capability to support multi-modal user interfaces.
The simplest form of using the annotation application for digitally augmenting paper documents is to enable
links from active regions to specific URLs. On link activation, a browser is started to visualise the
appropriate information. Through this simple mechanism, it becomes possible to have active citations. A
user no longer has to go to a library or even to turn to the bibliography at the end of the paper. Instead,
by just pointing to a printed citation, they get direct access to the digital version of the cited paper which,
if necessary, can then also be printed.
An activated link may lead to a simple resource, for example a PDF version for a citation that has been selected.
However, if a link has been defined to an object of the domain-specific application database, rather than just
to a simple web resource, additional information can be accessed. In addition to the title and list of authors
for the cited paper, through a dynamically generated web page one gets information about technologies that
have been used in the cited paper, other papers where the same technologies have been used etc.
One problem of such a system for handling scientific annotations is that while reading a paper, a user always
has to switch to the computer screen to view supplementary information. We therefore decided to design a
multi-modal user interface by taking advantage of XIMA's power to generate voice output. In addition to
returning the information about a citation’s title and other related information in textual form, XIMA
transforms this data to spoken output using text-to-speech (TTS) technology. This has the advantage that a
user can access multiple channels at the same time for gathering information. After selecting an active
area on a research paper, the user can go on reading while simultaneously listening to the voice
information about the linked resource.
Even without adding any additional digital information and using the digital media solely for defining
associations between research papers, the sharing of these links is a potent tool that somehow extends the
very static concept of today’s citations as used in research papers. In this way, new citations and links
to related work can be added to a research paper after it has already been published. If a user later
activates such an annotation, they either get access to digital versions of the associated documents or at
least get information about the title, the authors and the publisher of an associated document. Note that
by using the selector concept, it is not only possible to define entire documents as links targets but also
to reference specific parts of a document. The activation of such a paper-to-paper link not only returns
the title of a document which has been defined as a link target but also details about the page number
and where on that page the relevant information can be found. Further, by using a single iServer database
for multiple clients or applying the distributed iServer architecture, it becomes possible to collaboratively
build up a literature database together with experts in the same or other research domains.
We have introduced the publication annotation application as a tool for augmenting research papers and building
associations between them. However, the application domain is not limited to research papers only and can be
used to build up a knowledge base for any application domain based on paper documents and digital information.
By applying the distributed iServer approach, not only experts of the same research area can share their
knowledge, but also different research domains can be cross-linked forming a global information space.
Related Publications
2025
Pen-based Interaction,
Beat Signer,
Handbook of Human Computer Interaction, Major Reference Work, Springer Nature, 2025